Chain-of-Goals Hierarchical Policy for Long-Horizon Offline Goal-Conditioned RL
Abstract
Chain-of-Goals Hierarchical Policy (CoGHP) is a unified hierarchical policy for long-horizon offline goal-conditioned reinforcement learning. Instead of relying on separate high-level and low-level policies, CoGHP reformulates hierarchical decision-making as autoregressive sequence generation.
Given a current state and a final goal, CoGHP generates a chain-of-goals, a sequence of latent subgoals followed by the primitive action. Each latent subgoal serves as an intermediate reasoning step that guides subsequent predictions while preserving awareness of the final goal throughout the decision process.
Challenges
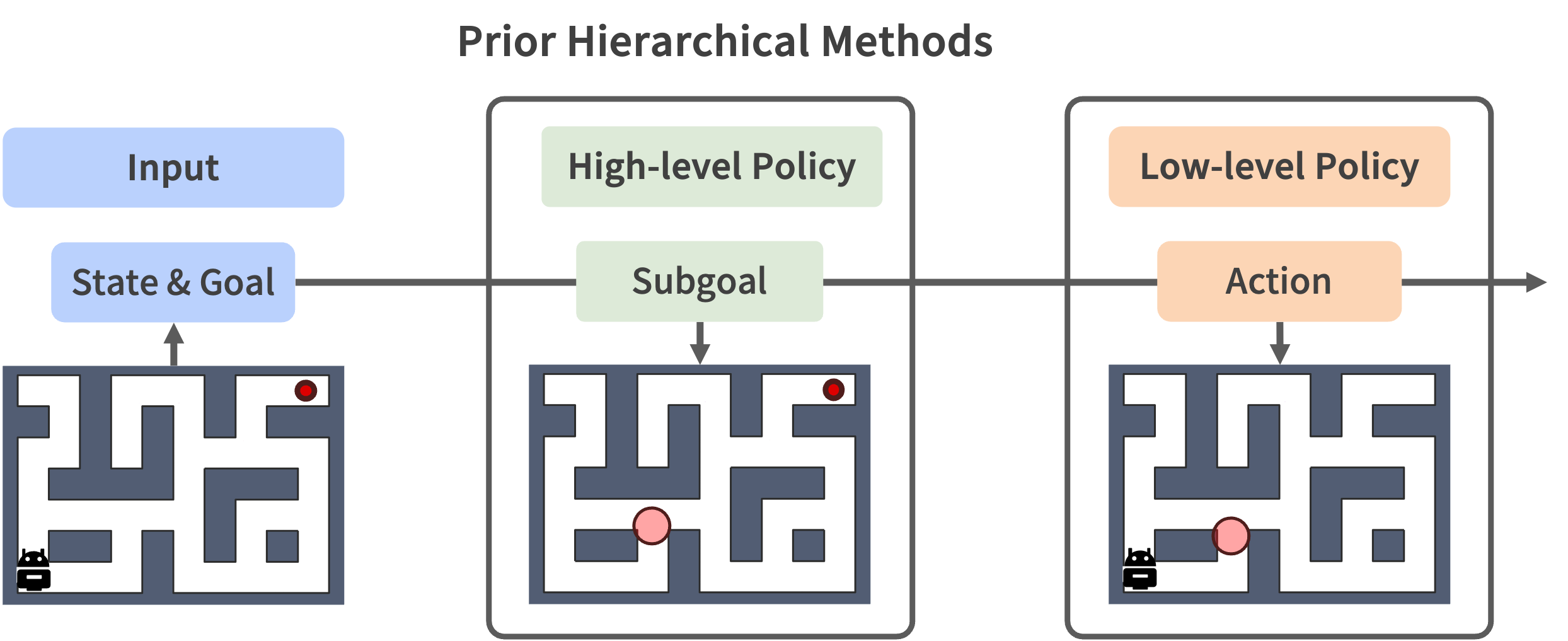
Existing offline hierarchical reinforcement learning methods often decompose long-horizon tasks into high-level subgoal selection and low-level control. While this decomposition is effective for temporal abstraction, it also introduces three structural limitations:
1. Single-Subgoal Abstraction
- A single intermediate subgoal may not capture complex multi-stage tasks.
- Many tasks require multiple intermediate decisions before reaching the goal.
2. Loss of Final-Goal Awareness
- A separated low-level policy may follow an imperfect subgoal while ignoring the final goal.
- This can lead to suboptimal actions in long-horizon tasks.
3. Fragmented Optimization
- Separate high-level and low-level objectives make end-to-end hierarchical learning difficult.
- Learning signals are split across hierarchy levels, limiting coordination.
These limitations motivate a unified framework that can generate multiple intermediate subgoals and the final action within a single model.
Main Idea
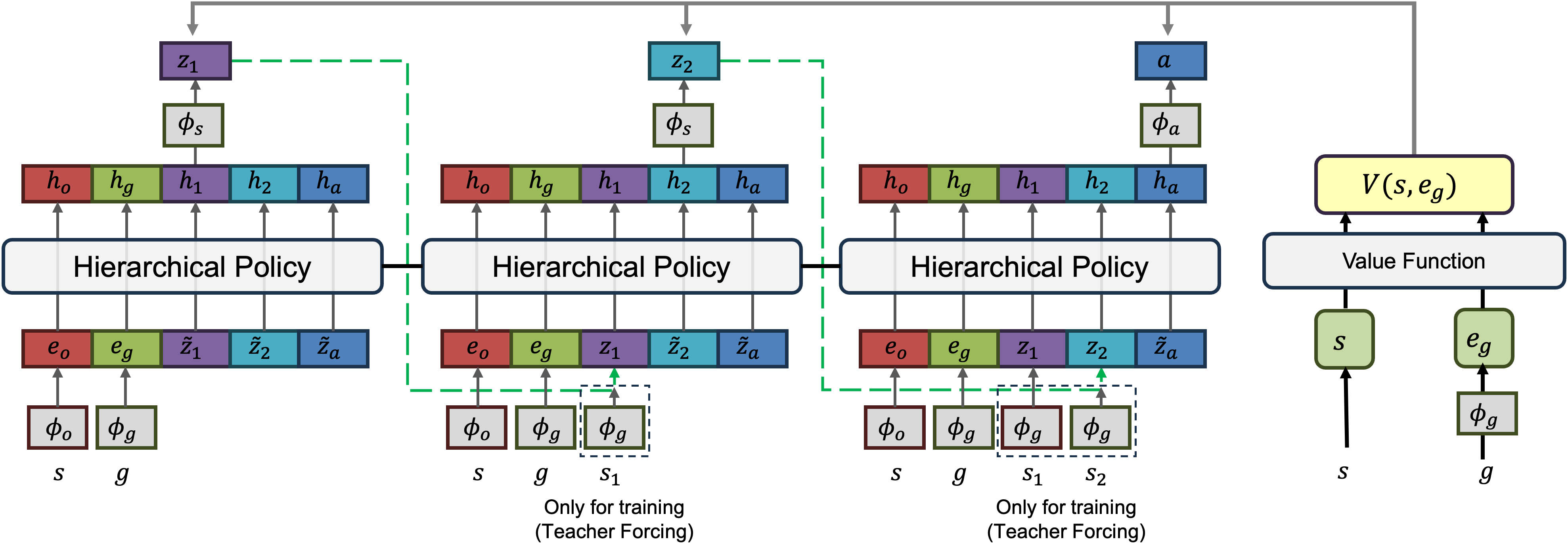
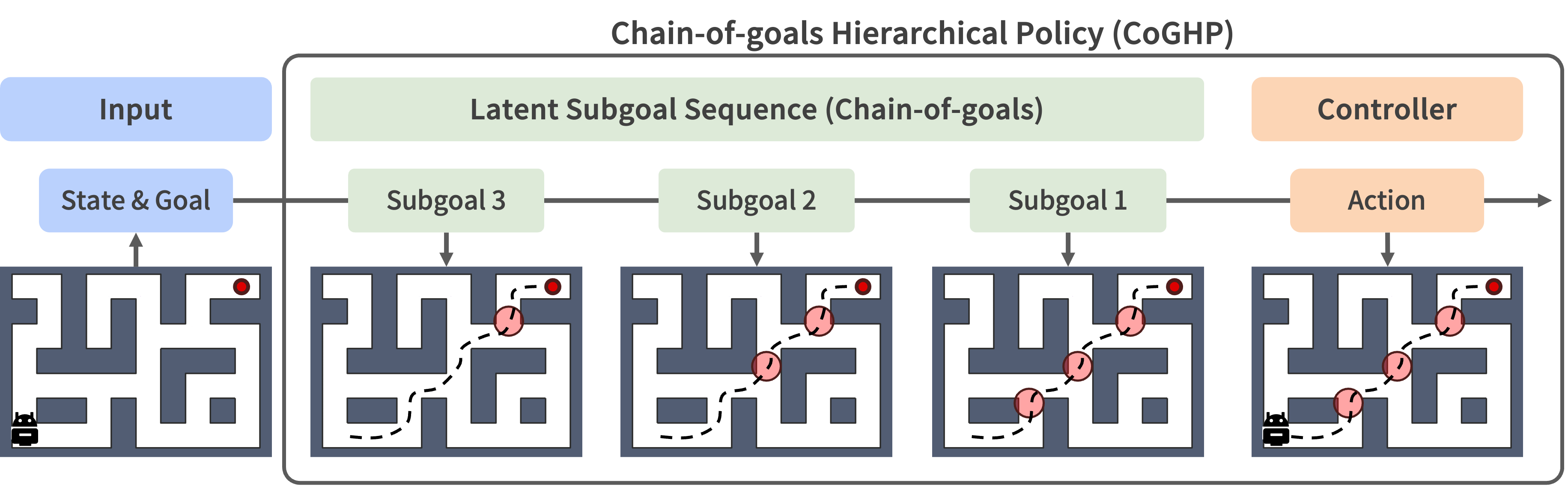
CoGHP turns long-horizon control into a chain-of-goals generation problem. Built on an MLP-Mixer-based hierarchical policy, CoGHP generates multiple latent subgoals from the current state and final goal, and then predicts the primitive action within a single unified model.
Generating a chain of goals
Instead of relying on a single intermediate target, CoGHP generates a sequence of latent subgoals that progressively bridge the gap between the current state and the final goal.
Each latent subgoal serves as an intermediate reasoning step, allowing the policy to represent long-horizon decision-making as a structured chain of goals rather than a single planning step.
State + Goal → Subgoal H → ... → Subgoal 1 → Action
Autoregressive Subgoal Generation
CoGHP generates subgoals one by one, so each prediction can depend on the previously generated subgoals.
- Multi-step decomposition: Long-horizon tasks can be broken down into several intermediate goals.
- Final-goal awareness: The final goal remains part of the input throughout the entire generation process.
- Unified decision-making: Subgoal generation and action prediction are trained together in a single model.
Why MLP-Mixer instead of Transformer?
Although this problem can be viewed as sequence modeling, CoGHP's token sequence is different from natural language. Each token has a fixed role:
current state | final goal | latent subgoals | action
In this structured setting, the flexibility of self-attention is not always necessary. CoGHP uses an MLP-Mixer backbone to efficiently exchange information across these fixed-role tokens through simple token-mixing and channel-mixing operations. This provides a suitable inductive bias for hierarchical decision-making while keeping the model unified and stable.
In short, CoGHP formulates long-horizon control as autoregressive chain-of-goals generation, producing a sequence of latent subgoals before predicting the final action.
Results
Quantitative Results

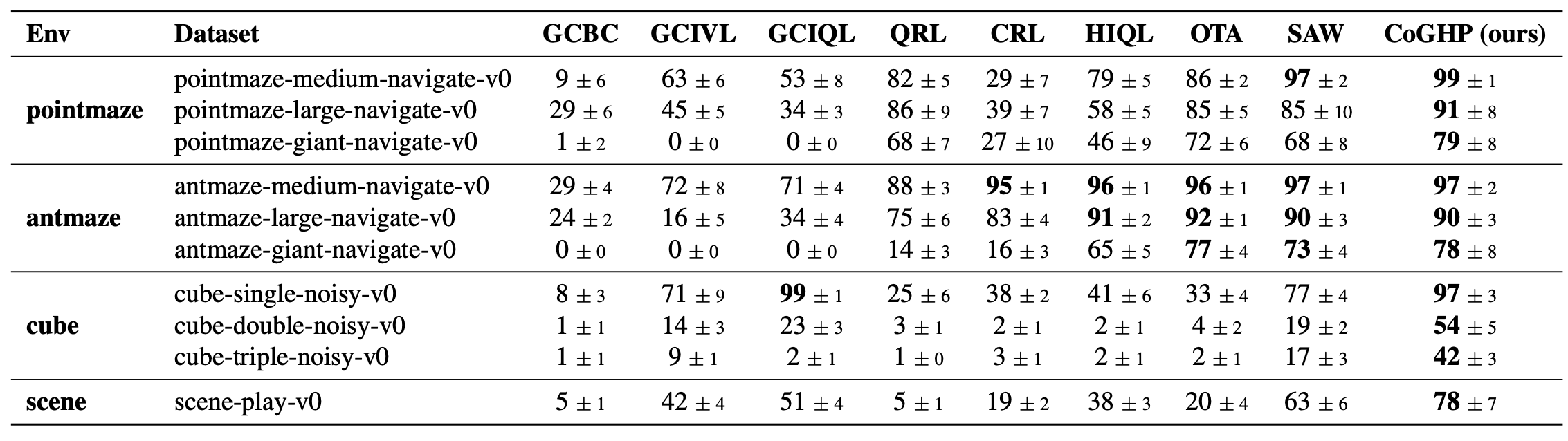
We evaluate CoGHP on challenging navigation and manipulation tasks from OGBench. CoGHP achieves strong performance across diverse environments, including PointMaze, AntMaze, Cube, and Scene tasks. In long-horizon navigation tasks, CoGHP shows clear gains in complex maze environments, where multi-stage reasoning is important. In manipulation tasks, CoGHP also performs strongly on sequential object interaction tasks, demonstrating the benefit of unified subgoal generation and action prediction.
Subgoal Visualizations
To better understand how CoGHP decomposes long-horizon tasks, we visualize the generated latent subgoals in AntMaze. The visualization shows that CoGHP produces intermediate subgoals along meaningful paths toward the final goal. These subgoals provide structured guidance for the policy, illustrating how the chain-of-goals helps the agent break down a complex task into a sequence of intermediate steps.
Citation
@article{choi2026chain,
title={Chain-of-Goals Hierarchical Policy for Long-Horizon Offline Goal-Conditioned RL},
author={Choi, Jinwoo and Lee, Sang-Hyun and Seo, Seung-Woo},
journal={arXiv preprint arXiv:2602.03389},
year={2026}
}The website template was partly borrowed from Michael Gharbi, and Jon Barron.